Building and Managing Web Sites with the Template Toolkit
Presented at the O'Reilly Perl Conference 4, July 2000
This paper addresses some of the issues involved in developing and maintaining web site content and web-based applications. It identifies some common problems encountered and presents some basic requirements for flexible content generation. It demonstrates the technique of using text-based template files to generate dynamic HTML and introduces the Template Toolkit, a set of Perl modules available from CPAN [1], ideally suited for this purpose.
A number of worked examples are presented which illustrate various features of the Template Toolkit. These demonstrate the construction of both static and dynamic HTML pages using the standard toolkit utilities, custom CGI scripts and Apache/mod_perl handlers. The use of standard plugin modules is included to demonstrate integration with CGI [2], XML [3] and DBI [4], and methods for extending the Template Toolkit by binding to external data and user-defined code are also covered.
The closing sections present an analysis of performance and a critique of the markup language syntax with regard to the inherent trade-off between simplicity and flexibility. The paper concludes by stressing the importance of adopting a suitable structure and methodology for building a web site, in addition to using the right tools for the job.
A typical web site will deliver content that has been generated in a number of different ways. Simplest of all are static pages that have been prepared in advance and are delivered directly from a file. Returning pages in this way is fast and efficient but inherently limited in that the content is fixed and cannot be adapted to reflect the mood of the moment. It isn't possible to affect a change in presentation style, incorporate some run-time data such as the results of a search engine or database query, or respond to any other kind of dynamic event such as the provision of CGI [2] parameters.
Maintaining a web site comprising of a large number of static pages is no easy task. While it may be feasible to manually edit a small number of files to add a new menu option or change a copyright message, this method doesn't scale well and tends to lead to inconsistencies between pages. Static pages are good for you, your web clients and the load on your web server, but it's generally best to think of them as being "Write Once, Read Many". Even with good application level support [5], editing large numbers of HTML files is time-consuming and prone to error.
The alternative is dynamic content generation where the HTML page (or other format) is created on-the-fly whenever a request is received for a particular URL. The obvious benefit is that you can perform any side-effect processing, customise the content and add any relevant dynamic data as you build the page. The main drawback is that it takes longer and consumes more in the way of system resources to build a page from scratch than it does to simply return one from a file.
Common approaches to generating dynamic content are to write a CGI [2] script (a stand-alone Perl program which is run each time a
particular request is received and generates HTML as output), or a
mod_perl [6] handler (a Perl module loaded into a Perl
interpreter inside the Apache [7] web server which defines a
sub-routine which gets called on each request and acts in the same way).
This solves the problem of building dynamic data into delivered pages
and makes it possible to use the web as a front end for an application
(i.e. where an HTTP request triggers some action before returning the
appropriate content), but doesn't make the maintenance of the pages any
easier. In fact, with fragments of HTML scattered in
print() statements amongst regular Perl code in different
parts of the filesystem, it becomes decidedly harder to make changes
that affect a significant part or all of a web site.
These are essentially programmatical approaches to content generation and in their basic form offer a powerful, no-nonsense approach to creating textual output. Over the past few years a number of other techniques have emerged with the goal (which hasn't always been met) of simplifying the generation of dynamic content.
At the end of the spectrum closest to purely programmatical solutions, we have embedded scripting languages that allow static documents to contain fragments of programming language code which are then evaluated at ``delivery'' time. PHP [8] and ASP [9] are examples of bespoke web scripting languages whereas Embperl [10] and the Text::Template module [11] opt for embedding real Perl code directly into documents.
This solution works well for generating individual dynamic pages, or multiple pages that conform to a similar format, but doesn't necessarily help in acheiving consistency between different parts of a web site. We have simply inverted the CGI script scenario so that the code is now in the HTML, instead of the HTML being in the code, but not made it significantly easier to update or maintain. It is certainly possible to apply a structured approach to embedding Perl by moving implementation code into reusable libraries or modules that are then called from the document code. Most bespoke languages provide inbuilt constructs to help better achieve this separation, permitting a more component-based approach to building content. While this certainly helps, it may require strict discipline from the developer to adopt such a strategy and without previous experience in such matters, they may not be even be aware of the right approach to take.
At the other end of the spectrum, we have techniques based on stylesheet processing such as CSS [12] or transformation of a structured language such as XML, as described in the XSL [13] and XSLT specifications [14]. These approaches allow us to easily customise the presentation of pages based on a single stylesheet or transformation specification, provide cross-site consistency and greatly reducing the maintenance burden. They naturally promote a highly structured approach, making it easier for the author to ``do the right thing'' to build flexibility and maintainability into a site from the start. The downside is often complexity and a quick glance at the above standards shows that understanding and utilising these techniques is a non-trivial task. Furthermore, there is little to offer in the way of support for adding dynamic functionality to any given page or for mapping such a generic presentation technique onto a web application.
Falling somewhere in between are a number of Perl modules, scripts and even full-blown content management systems and application servers [15] that provide widely differing levels of quality, complexity and functionality. Beyond that there are numerous implementations in other programming languages and countless commerical systems that provide different ways of doing roughly the same thing. Many of these were spawned from the original Server Side Include technique implemented in the original NCSA httpd web server.
A common theme running through these related approaches is the separation of presentation elements and optionally, application code, into reusable components. Template documents contain HTML fragments and separate code, objects or modules (where supported) implement application functionality. The different layers are bound together by a template processing system which parses the template documents and binds in other content and data according to the processing instructions embedded within. In some cases, the separation is very clear, where code is code and HTML is HTML and never the twain shall meet. But in far too many cases, there is no clean separation and code fragments are embedded liberally within document templates.
Some solutions are simple, providing only variable substitution, but are effective and can be adapted to almost any use. Furthermore, by warrant of their simplicity they force the user to write code externally and use the template only to fill in pre-calculated values. Whilst this avoids the entangling of implementation and presentation elements, it is limited in functionality and doesn't significantly improve the cross-site consistency or ease the task of content creation and maintenance. Larger systems may offer a richer functionality set and provide tools for easily constructing web applications and interfaces, but also may require significant "buy-in" to a certain architecture, style, platform or vendor.
Building a web page is easy and most of these tools perform admirably in this area. In the author's opinion, the best way to build a single dynamic page with as much power and requiring as little effort as possible, is to embed Perl using the Text::Template module. However, building a web site is considerably harder and requires more structure, thought and organisation. In addition to the basic requirement that we should have highly dynamic functionality in our pages, we must also give consideration to how the individual documents and applications in our web site will combine and interact to create a consistent and coherent information system.
The requirements for a content generation system to acheive this can be summarised as follows:
- Control over design aspects
-
It should be possible to apply a standard "look and feel" across an entire web site and be able to define this in one place. This may be characterised by layout, use of fonts, colour, images, etc., and other general presentation attributes.
- Cross-site consistency
-
A larger aspect of the above is the ability to define common template elements such as headers, footers, menus, etc., that can be included into other documents at will. This greatly improves the cross-site consistency given that all pages will contain exactly the same headers, etc., and as above, allows these elements to be defined in one place so that they can be easily changed and re-applied.
- Separation of code and presentation
-
To promote a structured approach to building content, it should be possible to clearly separate implementation code from presentation templates. This is beneficial in creating a better separation of concerns and even allows different people to develop code from those who design the output templates.
- Reusability
-
By moving code into separate modules and creating individual template elements, it should be possible to re-use these components as necessary to create new pages or modify existing pages with minimal effort. The system must provide a flexible way of binding these different components together.
- Maintainability and portability
-
Changes made to code should have minimal impact on HTML templates. Similarly, presentation elements should act independantly of any particular implementation of application functionality. In other words, we should be able to re-use existing code with a different set of output templates, or change the back-end implementation for an application while keeping the same look and feel. Furthermore, we should be able to apply the same techniques for managing the style of a document to managing structural or navigation elements of our web site, making it possible to relocate or restructure parts of the site. For example, by specifying URL's, image sources, etc., relative to a particular root variable, we can redefine the value of the root to effectively update all values that use it (e.g.
<img src="$images/logo.png">) - Environmentally friendly
-
The system should be unintrusive, placing minimal requirements on how and where it can be used. It should be possible to apply it equally well to generating static pages or delivering dynamic content online via CGI script, Apache/mod_perl handler or otherwise. It should work wherever Perl works.
The Template Toolkit [16] is a collection of Open Source Perl modules, freely available from CPAN [1], which collectively implement a flexible and powerful template processing system. It attempts to encompass the best of both worlds by combining the programming power of Perl with a simple template language designed for constructing presentation elements and formatting data. It promotes a strategy of clearly separating code from template documents and aims to be as simple as possible to use and to place as few restrictions on how, where and for what it can be used. It is quite simply a text processor and is entirely ignorant of any particular application or environment. Because of this, it can be used to process any kind of textual input and is equally proficient generating LaTeX, XML or POD as it is HTML. Furthermore, it can be used in CGI scripts, other "offline" Perl scripts to generate static pages, or embedded in an Apache/mod_perl environment. The modules are implemented entirely in Perl and should run on any platform on which Perl is available.
The rest of this paper will focus on the use of the Template Toolkit in generating and managing web content. It will attempt to illustrate by example how it solves the problems and meets the requirements identified above, by promoting a structured but flexible approach to developing web content.
To illustrate the basic syntax and structure of a Template Toolkit document, we will look at creating a simple static HTML page. We'll create this file as welcome.ttml, using our text editor of choice.
welcome.ttml
[% INCLUDE header %] <h1>Hello World</h1> <p>[% message %]</p> [% INCLUDE footer %]
In this example, the template directives are embedded using the
default [% ... %] characters,
but you can set various configuration options to redefine this.
Directives can span multiple lines and may contain additional
whitespace which is generally ignored. The syntax is deliberately
simple and variables like 'message' in the example above don't require
a leading '$' to distinguish them as such.
With the INTERPOLATE option set, you can embed Perl-like variables directly into document text as such:
<p>$message</p>
The INCLUDE token indicates a special directive
type rather a simple variable. In this case it causes the named
template files (header and footer, respectively) to
be processed and inserted into the current document in place of the
original directive. The directive type doesn't have to be specified in
upper case (unless you set the CASE option) but you may find it helps
to make it more visually distinctive.
We can now create the separate header and footer template files:
header
<html>
<head>
<title>Welcome to the 4th Perl Conference</title>
</head>
<body bgcolor="#ffffff">
footer
</body> </html>
These are just like any other template file and can contain their own directives. It's not particularly useful to have every page on the site use the same title, so we can define this and any other potentially dynamic items as variables:
header
[% DEFAULT
title = 'The 4th Perl Conference'
bgcolor = '#ffffff'
%]
<html>
<head>
<title>[% title %]</title>
</head>
<body bgcolor="[% bgcolor %]">
<div align="right">
[% INCLUDE menu %]
</div>
When we INCLUDE the template file, we can add local definitions for these variables:
[% INCLUDE header title = 'Hello World' %]
The header file will generate the enclosed HTML with the
title text 'Hello World' inserted at the approriate
place. The DEFAULT directive allows us to provide
sensible defaults for those times when values aren't specifically
provided. Undefined variables will otherwise produce no output.
We've also added the [% INCLUDE menu %] directive
to the header file to insert a menu of links. Here we show how the
FOREACH directive can be used to build repetitive
elements.
menu
[% FOREACH link = ['modules', 'authors', 'scripts'] %] [ <a href="[% link %]/index.html">[% link %]</a> ] [% END %]
We may choose to define the menu item as a separate template in its
own right, or we can use the BLOCK directive to
define a template fragment within the same file.
[% BLOCK menu_link %] [ <a href="[% link %]/index.html">[% link %]</a> ] [% END %] [% FOREACH link = ['modules', 'authors', 'scripts'] %] [% INCLUDE menu_link %] [% END %]
Now we can simply INCLUDE the 'menu_link' block
for each entry in the list as shown above, or simplify it even further
by rewriting the last directive as:
[% INCLUDE menu_link
FOREACH link = ['modules', 'authors', 'scripts']
%]
This simple approach of breaking web pages down into reusable common elements greatly reduces the time required to create pages. It allows changes to be made in one place which can then be permeated across an entire web site.
The Template.pm module is a general purpose wrapper around the Template Toolkit and provides a simple application interface for processing templates. A small Perl script like the following is all that is required to process the above template. Line numbers are shown here for convenience and are not part of the Perl program.
ttproc
01 #!/usr/bin/perl -w 02 03 use strict; 04 use Template; 05 06 my $file = shift || die "usage: $0 file\n"; 07 my $template = Template->new(); 08 09 $template->process($file) 10 || die $template->error();
We load the Template module in line 4, create a Template object in
line 7, and then call its process() method in line 9,
passing the name of the template file harvested from the command line
arguments in line 6. If the process() method returns a
false value, we retrieve the error message from the object and die. By
default, the process() method prints the processed
template to standard output.
Our welcome.ttml template file currently looks like this:
ttproc
[% INCLUDE header
title = 'Hello World'
%]
<h1>Hello World</h1>
<p>[% message %]</p>
[% INCLUDE footer %]
We can run the script and redirect the output to a file:
$ ./ttproc welcome.ttml > welcome.html
welcome.html
<html>
<head>
<title>Hello World</title>
</head>
<body bgcolor="#ffffff">
<div align="right">
[ <a href="modules/index.html">modules</a> ]
[ <a href="authors/index.html">authors</a> ]
[ <a href="scripts/index.html">scripts</a> ]
</div>
<h1>Hello World</h1>
<p></p>
</body>
</html>
We didn't provide any value for the 'message' variable so it was left
blank in the output. We can remedy this by defining a hash reference
of variables and associated values which we pass by reference to the
process() method.
my $data = {
message => 'Welcome to the 4th Perl Conference',
};
$template->process($file, $data)
|| die $template->error();
Figure 1 shows the HTML page now generated by the above.
{kind=link}
The tpage and ttree utilities, distributed as part of the Template Toolkit, can be used to automate much of the processing of template files and can often remove the need to write a Perl wrapper script at all. The tpage script contains little more than the previous example, simply creating a Template object and processing the file specified on the command line. The ttree utility is more extensive and can be used to build entire web sites with a single command. In essence, ttree is to template processing what make is to compiling source code.
In the previous examples, we used a '.ttml' extension for
our source file and '.html' for our destination. We could
continue to follow that protocol but ttree allows us to
specify separate source and target directories. Knowing that the
output will be written to a different directory, we can safely use the
same file extension without any worry of a processed file overwriting
a template file of the same name. These and other options can be
specified as command line options or in a configuration file such as
the following.
~/.ttreerc
src = ~/tpc4/examples/src dest = ~/tpc4/examples/html lib = ~/tpc4/examples/lib copy = \.gif$ ignore = \b(CVS|RCS)\b recurse pre_process = config
Template files in the source directory ('src') are processed and
written to the destination tree ('dest'). The 'lib' option specifies
one or more addition directories where template elements may be found
(e.g. header, footer, menu, etc). These are
added the the Template.pm INCLUDE_PATH option.
From the above configuration, ttree will create a Template
object as if written (for my value of '~' which is '/home/abw'):
my $template = Template->new({
INCLUDE_PATH => '/home/abw/tpc4/examples/lib',
PRE_PROCESS => 'config',
});
The PRE_PROCESS option specifies a template file
which should be processed before each document. This file should be
located in the 'lib' directory and can be used to initialise site-wide
variables. For example:
~/tpc4/examples/lib/config
[% root = '/~abw/tpc4'
home = "$root/welcome.html"
images = "$root/images"
author = 'Andy Wardley'
email = 'abw@kfs.org'
copyright = "&copy; $author 2000"
logo = { src => 'logo.gif', width => 40, height => 32 }
%]
[% DEAULT
message = 'Welcome to TPC4'
%]
With these variables defined we can now go back and improve on some of our template components. These should now be located into the 'lib' directory specified above.
~/tpc4/examples/lib/menu
[% BLOCK menu_link %] [ <a href="[% root %]/[% link %]/index.html">[% link %]</a> ] [% END %]
Here we redefine the menu link URL to be relative to the
'root' value. Not only does this mean that our menu will
now work wherever it is used in the site, but also that we can
relocate our site to a different root URL and rebuild new links by
simply changing this one value.
~/tpc4/examples/lib/footer
<hr> <div align="center"> [% INCLUDE menu %] [% IF copyright %] <p>[% copyright %]</p> [% END %] </div> </body> </html>
The IF directive above tests to see if the
'copyright' variable is defined and has some value. If true, it
processes the enclosed block up to the matching
END directive. These may be combined with
ELSE and ELSIF directives and
may be nested indefinately.
We can also add a logo template element which uses the values
specified in the 'logo' hash array to construct an image
tag which links to the home page. To access the individual hash
values, we use a dotted compound notation as shown below. This is a
general convention within the Template Toolkit and provides a
consistent method for accessing hash values (e.g.
'hash.somekey', 'hash.keys',
'hash.values'), list members (e.g. 'list.size') and object methods (e.g.
'object.method').
~/tpc4/examples/lib/logo
<a href="[% home %]"><img src="[% images %]/[% logo.src %]" border="0" width="[% logo.width %]" height="[% logo.height %]"></a>
Note that we define the image URL to be relative to 'images' which in
turn is defined relative to 'root'. This ensures that our
image links will remain correct if we need to relocate or modify the
structure of the site. We can now [% INCLUDE logo
%] in the header file, or indeed any other template file to
insert our hyperlinked image tags. Furthermore, we can provide
specific values to create a custom logo from the same template:
[% INCLUDE logo
home = 'http://www.perl.com/'
logo = { src => 'camel.png', width => 64, height => 64 }
%]
For a final flourish, we can define a global MACRO
in the config file, allowing us to use [% camel
%] as a shorthand form of the above:
[% MACRO camel INCLUDE logo
home = 'http://www.perl.com/'
logo = { src => 'camel.png', width => 64, height => 64 }
%]
Running the ttree script in verbose mode will display a summary of configuration options and files as they are processed. We can add documents to the 'src' directory at any time and run ttree to have them processed. For example, we can add index pages for our 'modules', 'scripts' and 'authors' directories. Here's a basic skeleton:
~/tpc4/examples/src/modules/index.html
[% INCLUDE header
title = 'Module List'
%]
<h1>Modules</h1>
[% INCLUDE footer %]
Then we can execute ttree:
$ ttree -v
ttree 1.16 (Template Toolkit version 1.04)
Source: /home/abw/tpc4/examples/src
Destination: /home/abw/tpc4/examples/html
Include Path: [ /home/abw/tpc4/examples/lib ]
Ignore: [ \b(CVS|RCS)\b, ^# ]
Copy: [ \.gif$ ]
Accept: [ * ]
- CVS (ignored, matches /\b(CVS|RCS)\b/)
- authors/index.html
- modules/index.html
- scripts/index.html
- welcome.html
Here we can see that the three new index.html files were processed along with the original welcome.html. We can point our web browser to our destination directory and view the pages (see Figure 2).
{kind=link}
These simple template techniques allow us to quickly build static web content from common interface components. The ttree utility helps to automate the build process so that changes can easily be made and quickly applied.
As we need to build greater functionality into our pages we must look beyond static pages and consider how we can apply these techniques to dynamic content generation. The earlier example using the Template.pm module is enough to form the basis of a simple CGI script. When we create the Template object, we will specify the same INCLUDE_PATH and PRE_PROCESS options that we defined for ttree. This will allow us to reuse the same template elements and ensures that the same variables are pre-defined for our CGI scripts as for our static pages. Note that we also add the 'src' directory to the INCLUDE_PATH, allowing us to specify a relative filename of welcome.html and have it loaded from the appropriate location.
#!/usr/bin/perl -w -T
use strict;
use Template;
use Date::Format;
# set STDOUT to auto-flush and print header
$| = 1;
print "Content-type: text/html\n\n";
my $file = 'welcome.html';
my $tdir = '/home/abw/tpc4/examples';
my $template = Template->new({
INCLUDE_PATH => "$tdir/src:$tdir/lib",
PRE_PROCESS => 'config',
});
my $data = {
message => time2str('%H:%M:%S %d %B %Y', time),
};
$template->process($file, $data)
|| die $template->error(), "\n";
To illustrate the most basic use of dynamic data, we use the
Date::Format, and specifically the time2str()
sub-routine, to format the current system time into the 'message'
variable which is displayed as before (see Figure 3).
{kind=link}
This shows how we can acheive the same presentation consistency between CGI scripts and static pages. We can freely reuse template elements to build content irrespective of the generation technique.
Now let us look at how the advanced data and code binding facilities
of the Template Toolkit allow us to create truly dynamic content. The
process is trivial:- simply provide additional hash, list, code or
object references in the variables data hash and reference the items
by name in the templates. The Template Toolkit will translate these
variable references into the relevant action for the data type. Code
references are called, as are object methods of the form
'object.method', and additional parameters may also be provided. Hash
references will be indexed correctly when specified in the form
'hash.key' and list references can similary be indexed by 'list.n' or
iterated over using the FOREACH directive. Data
types may be nested indefinately and will be correctly traversed (e.g.
a sub-routine returns an object reference which has a method returning
a list of hash references, and so on).
In this example, we will define the following template variables.
- time
-
References a sub-routine which returns a formatted time/date string for the current system time. Parameters may be specified to define a new format or provide an alternate time value.
- filemod
-
The modification time of the current CGI script ($0).
- cgi
-
A reference to a newly instantiated CGI object.
The modifcations to the script are to load the CGI module, define the
new template variables and the format_time() sub.
...
use CGI;
...
my $data = {
time => \&format_time,
filemod => (stat $0)[9],
cgi => CGI->new(),
};
sub format_time {
my $format = shift || '%H:%M:%S %d %B %Y';
my $time = shift || time;
time2str($format, , $time),
}
We can now update our template to use these additional variable bindings.
[% INCLUDE header
title = "Hello World by CGI"
%]
<p>[% time %]</p>
<b>CGI Parameters</b>
<ul>
[% FOREACH item = cgi.param %]
<li>[% item %] => <b>[% cgi.param(item) %]</b>
[% END %]
</ul>
<div align="center">
Script last modified
at [% time('%H:%M:%S', filemod) %]
on [% time('%d %B %Y', filemod) %]
</div>
[% INCLUDE footer %]
Here we show the use of the 'time' variable both without, and then
twice with additional parameters. In the latter cases, we provide
custom format masks and use the 'filemod' variable to specify the time
we require formatting. This variable is automatically evaluated and
its current value passed to the format_time()
sub-routine. We also directly reference the param()
method of the CGI object bound to the 'cgi' variable. It is first
called in a list context without any arguments as the target of a
FOREACH loop. It is called again for each
iteration through the loop to retrieve the value for each item.
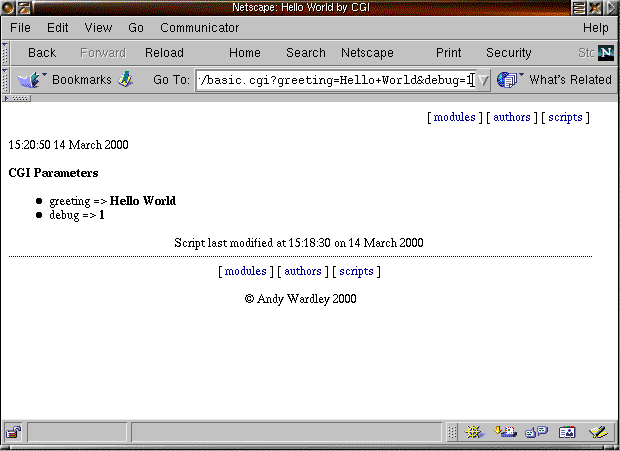
Figure 4 shows the output of our CGI script.
{kind=link}
We would like to make our CGI code generic and reuse common
functionality as much as possible. We can create Perl libraries or
modules to achieve this and load and bind them to variables as
required as per the earlier CGI.pm example. The Template Toolkit also
supports a simple plugin interface which allows extension modules to
be loaded on demand from a template document. The is implemented by
the USE directive.
[% USE CGI %] [% FOREACH item = CGI.param %] ...
This will load the CGI Template Toolkit plugin which in turn loads the CGI.pm module and initialises a CGI object instance. This is then assigned to the 'CGI' variable, or an alternate one specified as such:
[% USE cgi = CGI %] [% FOREACH item = cgi.param %] ... [% END %]
The DBI Template Toolkit Plugin [17] is a similar wrapper
around the DBI modules [4]. It connects to a specified data
source and allows SQL queries to be submitted via the
query() method.
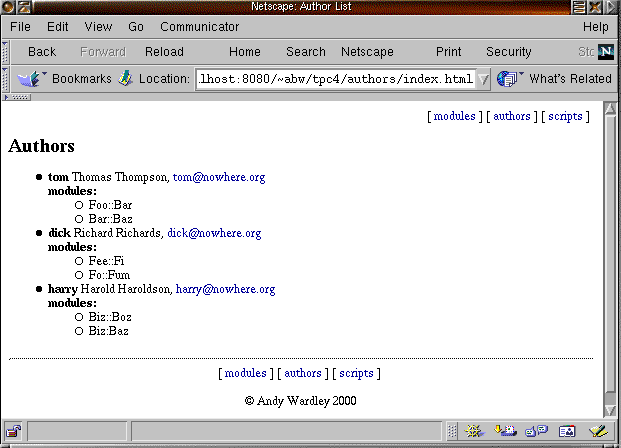
[% INCLUDE header
title = 'Author List'
%]
<h1>Authors</h1>
[% USE dbi = DBI('dbi:mSQL:tpc4') %]
<ul>
[% FOREACH author = dbi.query('SELECT * FROM authors') %]
<li><b>[% author.id %]</b> [% author.name %],
<a href="mailto:[% author.email %]">[% author.email %]</a>
[% END %]
</ul>
[% INCLUDE footer %]
Figure 5 shows the page generated by this template.
{kind=link}
The XML::RSS plugin is a further example showing how an XML document format such as RSS [18] can be parsed and then presented accordingly using HTML templates. A fragment of an RSS file, which allows the succinct expression of short news headlines, might look like this example extracted from http://slashdot.org/slashdot.rdf .
<item> <title>DVD CCA Battle Continues Next Week</title> <link>http://slashdot.org/article.pl?sid=00/01/12/2051208</link> </item> <item> <title>Matrox to fund DRI Development</title> <link>http://slashdot.org/article.pl?sid=00/01/13/0718219</link> </item>
A template to display the RSS news items might look like this:
[% INCLUDE header
title = 'Here is the News'
%]
<h2>News Items</h2>
[% USE news = XML.RSS('newsfile.rdf') %]
<ul>
[% FOREACH item = news.items %]
<li><a href="[% item.link %]">[% item.title %]</a>
[% END %]
</ul>
[% INCLUDE footer %]
These examples show how plugins can be used to load dynamic functionality into template documents without requiring a CGI or other wrapper script. Where data is relatively static and the data set reasonably small or available disk space sufficiently large, it may be beneficial to regenerate static views of a database, news file, etc., either on a periodic basis or on demand when items are added or updated, rather than maintain a dynamic view regenerated for each request. Where real-time dynamic data must be incorporated, to display the results of a search query for example, the same template authoring techniques can be used but with the template processed dynamically for each request.
Our CGI examples have been functionally sound but possibly lacking in performance. Invocation of a CGI script from a web server requires a child process to be spawed and Perl itself to be loaded which must then read and compile the program script and any other modules used. Once Perl actually gets to running the program it offers good performance, often falling within an order of magnitude of compiled 'C' code. Using Apache [7] and mod_perl [6] we can eliminate much, if not all of this per-request startup cost and acheive far better performance without sacrificing flexibility.
In the Apache httpd.conf file, we can request that the Template, and any other common modules be loaded at server startup time. We will also load a custom MyHandler.pm module in which we define a mod_perl handler routine.
~apache/conf/httpd.conf
PerlModule CGI PerlModule Template PerlModule MyHandler
We also set a Perl variable defining the root location of our template files. The MyHandler.pm module will use this value.
PerlSetVar Template_root /home/abw/tpc4/examples
Finally, we define a location and specify the MyHandler module as the handler.
<Location /templates>
SetHandler perl-script
PerlHandler MyHandler
</Location>
The module to handle these requests could be implemented as follows:
package MyHandler;
use strict;
use vars qw( $VERSION );
use Apache::Constants qw( :common );
use Template;
$VERSION = 3.14;
sub handler {
my $r = shift;
# get config value of Perl var 'Template_root'
my $troot = $r->dir_config('Template_root')
or return fail($r, SERVER_ERROR,
"'Template_root' not specified");
# create a template processing object
my $template = Template->new({
INCLUDE_PATH => "$troot/src:$troot/lib",
OUTPUT => $r, # direct output to Apache request
PRE_PROCESS => 'apache/config',
});
my $params = {
req => $r,
uri => $r->uri,
};
# use the path_info to determine which template file to process
my $file = $r->path_info;
$file =~ s[^/][];
$r->content_type('text/html');
$r->send_http_header;
$template->process($file, $params)
|| return fail($r, SERVER_ERROR, $template->error);
return OK;
}
sub fail {
my ($r, $status, $message) = @_;
$r->log_reason($message, $r->filename);
return $status;
}
The Apache request object is passed as the first parameter through
which we determine the configuration value for the 'Template_root'
variable. This is then used to define the
INCLUDE_PATH option when subsequently creating a
Template object. The OUTPUT option redirects
template output to the request object via its print()
method. A PRE_PROCESS file is specified which
modifies the values set by the original configuration file.
~/tpc4/examples/lib/apache/config
[% PROCESS config %] [% root = '/templates' home = "$root/welcome.html" images = "$root/images" %]
The template filename is extracted from the path_info element of the request. In this example, it will be the remainder of the URL following '/templates'. Thus, the URL '/templates/foo.html' is mapped to the template file 'foo.html' in the 'src' directory. The template object is used to process the file, passing a hash array of variables containing references to the request and URI items. Any other variables could of course be included at this point.
We can now use this handler to dynamically view template documents in our source directory. Templates may individually load resources via the USE directive and integrate dynamic functionality as necessary. The pages are built using the same element files as our CGI scripts and static pages, reducing the development time and improving consistency.
By using mod_perl over CGI we cut down on individiual request startup time but we're still parsing and processing the template documents for each request. We can improve the above handler so that it uses a single Template object reference created and stored in a package variable. All subsequent handler invocations reuse this reference, allowing it to parse once and then cache compiled templates.
The handler is modifed as follows:
use vars qw( $VERSION $template );
...
sub handler {
my $r = shift;
return fail($r, SERVER_ERROR, '$MyHandler::template not defined')
unless $template;
my $params = {
...
$template->process($file, $params, $r)
|| return fail($r, SERVER_ERROR, $template->error);
return OK;
}
The '$MyHandler::template' package variable can be
initialised by a Perl startup file.
~apache/conf/startup.pl
use MyHandler;
my $troot = '/home/abw/tpc4/examples';
$MyHandler::template = Template->new({
INCLUDE_PATH => "$troot/src:$troot/lib",
PRE_PROCESS => 'apache/config',
});
1;
~apache/conf/httpd.conf
PerlRequire conf/startup.pl
Because the Template object must now process templates for multiple
requests, we cannot define the OUTPUT option as
before. Instead, we pass the Apache request object as the third
parameter to the process() method, defining an output
redirection to the request object for the scope of that call.
Processing dynamic content is naturally slower than delivering static pages and adding content generation tools like the Template Toolkit increases the startup time required for Perl to load, parse and compile the modules. Furthermore, template documents must be parsed to separate directives from plain text and then processed to generate and/or output these elements accordingly.
The Template Toolkit uses Perl's superior regular expression facility to tokenise the text and a fast LALR(1) [19] parser based on the Parse::Yapp module [20] to compile templates into an intermediate form. The compiled templates are optimised for fast processing and are cached for subsequent use.
At the time of writing, version 2.00 of the Template Toolkit is in alpha test. It uses an enhanced parser back-end to rewrite template documents as valid Perl sub-routines which are then evaluated and cached as code references. For example, a template written as:
[% INCLUDE header title = 'Hello World' %] <h1>Hello World</h1> <p>[% message %]</p> [% INCLUDE footer %]
is rebuilt as something approximating the following:
sub {
my $context = shift;
$context->process('header', { title => 'Hello World' });
print "\n\n<h1>Hello World</h1>\n\n<p>\n";
print $context->get_variable('message');
print "</p>\n\n";
$context->process('footer');
}
This is then evaluated and stored as a reference to an anonymous sub-routine. The template is processed by calling the code, passing a reference to the current template processing object. This context reference provides access to the functionality of the toolkit for processing other template files, retrieving variable values and so on.
This improves the run-time effeciency to the point of competing with hand-written content generation sub-routines, but with all the inherent flexibility that the Template Toolkit provides. This also permits "compiled" templates to be written to disk in the latter form for subsequent cache persistance and significantly faster re-parsing. The current stable release version, 1.04, uses a slightly inferior (for these purposes) approach based on evaluating a sequence of opcodes. This is approximately 30-40% slower than the above technique but still represents a relatively fast and efficient solution. Version 2.00 should be available by the time of the Perl Conference.
CGI scripts have a naturally high startup time. A child process must be spawned, Perl must be loaded and itself must load and compile the specific script and any additional modules files. The output template must additionally be parsed and processed, adding to the execution time of the application code itself. When used in an Apache/mod_perl environment these time efficiency issues all but disappear. The loading and compiling of Perl modules is done at server startup time and a persistent Template.pm object can be used to cache compiled pages across requests. This means that common pages elements and even complete content pages can be cached and delivered quickly and repeatedly from their compiled form.
A further benefit of the Template Toolkit is in allowing you to easily
build and re-build static pages containing dynamic content. You don't
always need to build your entire web site from dynamically generated
components when you can change all of your static pages in an instant.
It's also possible to use different ttree configurations to
build multiple HTML trees from one set of source templates. By
modifying the INCLUDE_PATH to use elements in one
directory before another, it is possible to create an alternative view
of a web site by supplying new or modified templates to be used in
place of the old. The original templates remain unmodified and can
continue to be used to create the original interface. For example, you
can create interface elements localised for different spoken languages
and use these, where defined, in preference to the English defaults.
e.g.
# Japanese, or English defaults INCLUDE_PATH => "$troot/ja/lib:$troot/en/lib" # German, or English defaults INCLUDE_PATH => "$troot/de/lib:$troot/en/lib"
Pages that subsequently [% INCLUDE somefile %]
will be delivered the template from the first directory if it exists,
or from the second if not.
This technique can be applied to localising or customising the look and feel of the web pages in almost any way. It is possible to created themed versions of a site, separate text-only or minimal graphics variations, customise content for a particular protocol or format such as WAP [21], or in response to a user or client-specific configuration. By the fact that we can highly customise our static pages we can often reduce the need to deliver dynamic content at all. When we must deliver dynamically, we can do so efficiently using mod_perl, or at reasonable speed but possibly greater developer convenience by CGI script.
The Template Toolkit markup language aims to be as simple as possible while maintaining a close similarity to Perl. Variable definitions including hash arrays and lists, and function calls, for example, can exactly copy Perl syntax. e.g.
$user = { name => 'Andy Wardley', id => 'abw' }
$list = [ $foo, $bar, 'baz' ]
$result = do_something($x, $y, $x)
In most cases, the leading '$' is optional on variables and the above can be simplified as follows:
user = { name => 'Andy Wardley', id => 'abw' }
list = [ foo, bar, 'baz' ]
result = do_something(x, y, z)
While the former is especially useful for Perl hackers who might add the "correct" syntax without thinking, the latter is recommended for simplicity, if nothing else. Although it might be troublesome to learn a new syntax, it's no different (and about as simple) as understanding basic HTML or XML syntax.
[ NOTE: From version 2 onwards, the leading optional '$' is no longer supported. Variable should be written as 'foo', 'bar', 'baz', etc., and not '$foo', '$bar' or '$baz'. ]
The dotted compound notation represents a departure from regular Perl syntax but is a familiar construct in many environments. It has a number of benefits, the first of which is simplicity. In our template document we should be concerned with how the final page will look, and not how each item of data is stored or calculated. It helps us to acheive a clearer separation of concerns if we can think of a variable as being merely a placeholder for some value or function and not have to worry about implementation or storage specifics. At the presentation layer, we're concerned only with textual data and as long as there is a value to display when we need it, then we don't need to worry how one particular language or implementation is representing it internally.
$hash->{'key'} vs hash.key
$object->method($foo) vs object.method(foo)
$list->[6] vs list.6
scalar @$list vs list.size
Dispensing with all that distracting syntax certainly makes things more readable. In a traditional scripting language this might be less than ideal, where simplicity in syntax can often be a limiting factor in the power and expressiveness of a language. However, it is important to note that the Template Toolkit language is designed for page markup and is not intended to be a general purpose programming language. The intent is to move code out of the template documents rather than finding better ways of moving it back in. By providing a rich set of binding constructs to external Perl data and code, we hope to acheieve a simplicity in the presentation layer without limiting the programming flexibility available to the back-end developer.
A further benefit may also be apparent. By removing any syntax that specifically ties a variable to an underlying data type, we can change the implementation of our data model with no affect on the output templates.
The template variable
[% user.name %]
might conceivably be resolved as any of the following operations.
- 'user' is a hash array, 'name' is a key
- 'user' is a sub-routine returning a hash array as above
- 'user' is an object, 'name' is a method
As long as we implement one of the above it doesn't actually matter which. We can change the underlying data model within reasonable limits and continue to use the same presentation templates unchanged.
This clear abstraction also has the benefit of allowing different people to design HTML templates from those who develop the data model and implementation code. Having agreed on what must be provided by the developer and a basic interface defining the data items to be made available, the designer can create the output templates using 'dummy' values for variables and simply adopt the real data and code as it becomes available. German car rental company Sixt (http://www.sixt.com/) recently re-developed their web site and online booking system using the Template Toolkit. Content designers in Germany provided the HTML templates while coders in Slovenia developed the Perl modules to implement the functionality. They checked code and templates into a common CVS repository from which a build could be made at any time. Components were integrated smoothly and without incident despite the fact that the two teams never met or worked together in person.
There are many different Perl tools for generating dynamic web content, falling into roughly three categories; those that embed Perl directly into template documents, those that use bespoke scripting languages, and those that implement a more restricted document markup language with code elements being implemented in separate files. This latter approach is that of the Template Toolkit and one which allows it to offer a clean separation of concerns between the programmer(s) and designer(s) responsible for providing web content. Even when both aspects are provided by the same person, the ability to focus on the presentation or the implementation at any one time, simplifies the process by which web site content can be created and subsequently maintained.
One problem common to this kind of solution can be described as the functionality versus complexity trade-off. The desire to add ever-more powerful functionality to a system can lead to an increase in language and syntax complexity. This then reduces the presentation layer simplicity and marks a return to embedding application functionality in template language fragments. The markup language has become a programming language and the clear separation of concerns is blurred.
The Template Toolkit provides constructs for assigning and evaluating variables, testing expressions, iterating through loops, and other basic flow control functionality, but delegates all serious programming tasks to Perl. The language is designed for iterating through and formatting data rather than actually building, calculating or retrieving it. It is for constructing web pages from reusable code and template components but not for implementing any specific web application functionality. However, by simplfiying the generation and handling of the presentation layer, the development of application code becomes more focused and productive.
The problem arises that it is not always possible to acheive this clear separation, or in doing so one reduces the simplicity of design or must sacrifice some runtime efficiency. Sometimes, you really do need to write complex code to create a presentation element. Sometimes, it is easier for a code handler to quickly generate and output some presentation element than process a template element to create it the ``right way''. Sometimes the presentation logic can be inextricably bound into a computational cycle so that you have no choice but to add code to the template, add presentation elements to the code, or effect some kind of complex negotiation between the two.
The Template Toolkit is pragmatic rather than dogmatic and supports an
EVAL_PERL option which can be enabled to allow
real Perl code to be embedded within [% PERL %]
... [% END %] blocks. It's often better to get the
job done quickly and spend some time documenting dependencies and
hard-coded data than waste days or weeks building a perfectly
abstracted system that is too complex for anyone to understand. You
don't have to use it if you don't want to, but it's there if you do,
although disabled by default.
The methodology and structure that you apply to building your site is in many ways more important than any specific tool or language that you might use. We have shown how separating user interface elements allows us to combine them at will with other elements and code modules. Reuse of template elements brings us cross-site consistency and allows a look and feel to be easily changed and applied across a whole site. By applying these techniques to both static and dynamically generated content, we can be sure of maintaining these benefits no matter how we chose to build it. Keeping our code separate from HTML templates allows both to be reused or adapted as required with minimal impact.
The Template Toolkit is naturally well-suited for these purposes, being a second generation tool designed with these particular goals and design philosophies in mind, but that doesn't mean it is the definitive answer for all template processing needs. In the author's opinion, the best tools are those that do one thing and do it well. The Template Toolkit attempts to achieve this goal by implementing little in the way of application specific functionality itself, but instead providing an efficient means of constructing template components and delegating other tasks out to external code or modules. Thus we can hope to limit the functionality that must be provided in the template markup language without restricting flexibility, extensibility or ease of use.
| [1] | CPAN, Comprehensive Perl Archive Network, http://www.cpan.org/ |
| [2] | CGI, Common Gateway Interface, http://www.w3c.org/CGI |
| [3] | XML, Extensible Markup Language, http://www.w3c.org/XML/ |
| [4] | DBI, Database independant interface for Perl, Tim Bunce, http://www.arcana.co.uk/technologia/perl/DBI |
| [5] | Emacs. http://www.emacs.org/ |
| [6] | mod_perl, Embedded Perl interpreter in the Apache HTTP server, Doug MacEachern, http://perl.apache.org/ |
| [7] | Apache HTTP server, Apache Group, http://www.apache.org/ |
| [8] | PHP, Perl Hypertext Processor, PHP Development Team, http://www.php.net/ |
| [9] | ASP, Active Server Pages, Microsoft Corporation, http://www.micrososft.com/ |
| [10] | Embperl, Gerald Richter, ftp://ftp.dev.ecos.de/pub/perl/embperl/ |
| [11] | Text::Template, Mark-Jason Dominus, http://www.cpan.org/authors/id/MJD/ |
| [12] | CSS, Cascading Style Sheets, http://www.w3.org/Style/CSS/ |
| [13] | XSL, Extensible Stylesheet Language, http://www.w3.org/Style/XML/ |
| [14] | XSLT, XSL Transformations, http://www.w3.org/TR/1999/REC-xslt-19991116 |
| [15] | Iaijutsu, Leslie Michael Orchard, http://www.ninjacode.com/iaijutsu/ |
| [16] | Template Toolkit, Andy Wardley, http://www.cpan.org/authors/id/ABW/ |
| [17] | Template Toolkit DBI Plugin, Simon Matthews, http://www.cpan.org/authors/id/S/SA/SAM/ |
| [18] | RSS, RDF Site Summary, http://my.netscape.com/publish/help/mnn20/quickstart.html |
| [19] | LALR(1), see Aho, Alfred V., Sethi, Ravi, & Ullman,
Jeffrey D.,
Compilers. Principles, Techniques and Tools, Addison-Wesley, 1986 |
| [20] | Parse::Yapp, Perl extension for using and generating LALR parsers, Francois Desarmenien, http://www.cpan.org/modules/by-module/Parse/ |
| [21] | WAP, Wireless Application Protocol, http://www.wapforum.org/ |